[논문요약] AFL++: Combining Incremental Steps of Fuzzing Research
올해 1월부터 Fuzzing 관련 프로젝트를 시작하면서, 예전에 BoB 과제로 받았으나 전부 읽지는 못했던 AFL++ 관련 논문을 읽었다. 아쉬운 영어 실력이지만 내가 이해한 내용을 정리하면서 읽었는데, 영어 논문을 읽는데 버거운 사람들에게 도움이 되었으면 하는 마음으로 이를 공유하고자 한다. 논문의 출처는 다음과 같다.
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. “AFL++: Combining incremental steps of fuzzing research”. In 14th USENIX Workshop on Offensive Technologies (WOOT 20). USENIX Association, Aug. 2020.
0. Abstract
이 논문에서는 AFL++을 소개한다. 이는 state-of-the-art fuzzing 연구를 포함한, 커뮤니티 기반의 오픈소스 툴이다. 또한, 이 툴은 여러 가지 새로운 특징을 제공하는데, Custom Mutator API도 그중 한 가지이다. 이로 인해, Mutator 부분을 테스터의 입맛에 맞게 변형할 수 있다.
2. State-of-the-Art
이 장에서는 가장 성공적인 coverage-guided fuzzer인 AFL에 대해서 이야기를 할 것이다. 이 퍼저의 깊이 측면에서 더욱 개선하고자 한 지난 몇 년 간의 연구를 가능한 한 요약하여 보여줄 예정이며, AFL++에 대한 내용은 3장에서 확인할 수 있다.
2.1 American Fuzzy Lop
AFL은 coverage를 기반으로 입력을 변형하는 퍼져이다. 아직 프로그램에서 도달하지 않은 부분을 실행하기 위해 입력을 변형하며, 새로운 코드에 도달했다면, 이것이 테스트 큐에 저장된다.
2.1.1 Coverage Guided Feedback
AFL은 한 번 실행했을 때, 개별 edge가 얼마나 실행되는지에 대한 edge coverage를 기반으로 피드백을 수행한다. count는 2의 제곱 형태로 저장되며, 이를 통해 path explosion을 방지한다. 새로운 edge에 도달할 경우, 이 입력을 흥미롭다고 간주한다. 이러한 bucket, hitcounts들은 실행 중에 공유 메모리맵에 로깅되며, 그 크기가 제한적이기 때문에 충돌이 발생할 수 있다.
기존의 code coverage는 해당 블록이 실행되었는지만을 체크하였다. A 이후에 B가 실행되었을 때, 단순히 A와 B가 측정되는 것이다. 그러나, edge code coverage는 블록의 변화까지도 체크한다. A 이후에 B가 실행되었을 때, A->B의 관계가 표시되도록 측정을 한다는 의미이다. 이상적으로 표현을 하면, 이러한 전환은 튜플로 표현되는 것이 좋다. (e.g. A→C = (A, C)). 하지만, AFL은 그 뿌리를 파이썬에 두고 있는 퍼져가 아니다. 그렇다면, 도대체, AFL은 이러한 edge code coverage를 어떻게 저장할까?
1
2
3
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
컴파일 중 랜덤으로 설정되는 값을 cur_location에 넣고, prev_location과 cur_location을 xor하여 나온 값을 인덱스로 하여 shared_mem이라는 전역으로 접근 가능한 공유 메모리의 값을 늘린다. 그리고, prev_location을 cur_location의 시프트 연산을 수행한 값으로 수정한다. cur_location이 가리키는 값은 현재 블록의 고유한 ID이고, prev_location은 이전 블록의 고유한 ID라고 보면 된다. prev_location의 초기 값은 당연히 0이었을 것이고, 이 두 무작위 값을 XOR 연산함으로써, 고정된 길이의 해시를 만든다고 이해하면 된다. 그리고, 마지막 비트 연산을 수행한 뒤, prev_location 변수에 값을 넣는 이유는, A->B의 해시와 B->A의 해시를 구분하기 위함이다.
2.1.2 Mutations
변이를 어떻게 하느냐가 퍼징에 있어서 중요한 과제 중 하나이다. 변이를 너무 조금 일으키면, 좋은 커버리지에 도달할 확률이 줄어들고 제자리를 맴돌 것이다. 변이를 너무 격렬하게 일으키면, 초기 단계에서 터지는 테스트케이스가 많이 만들어질 것이다. 그 사이 중도를 지켜야 하는데, AFL은 다음과 같은 세 단계의 해결책을 제시한다.
- Deterministic
- 결정론적 단계에는 비트 플립, 특이한 수(-1, 0, INT_MAX)와의 간단한 덧/뺄셈 등을 포함한다. 이 단계가 결정론적인 이유는 특정한 입력 값이 들어오면, 언제나 같은 과정을 거쳐서 같은 결과를 내 놓는 알고리즘이기 때문이다.
- Havoc
- 입력의 크기를 변형(adds or deletes portions of the input)하는 것을 포함해, deterministic한 방법을 여러 개를 stack하여 사용한다.
- Splice
- 이전의 모든 단계에서 흥미로운 입력(새로운 경로)을 발견하지 못했을 때, 수행된다. 서로 다른 입력을 큐에서 재조합하는데, 최소한 둘 이상의 위치에서 합친다. 이렇게 재조합된 입력이 다시 havoc 단계로 진입한다.
2.1.3 Forkserver
execve()의 오버헤드를 피하기 위해서, AFL은 forkserver를 사용한다. fuzzer가 forkserver를 만들고, Interprocess Communication(IPC) 메커니즘으로 대상 프로그램을 관리한다. AFL이 테스트케이스를 넣을 필요가 있을 때, 입력을 작성하고, 그 후에 대상 프로그램이 스스로 fork하게 한다. 자식 프로세스가 테스트케이스를 실행할 것이고, 부모 프로세스는 이것이 끝날 때까지 기다린다. forkserver는 이후에도 target에서 fork할 수 있다. 이를 통해, fuzzer는 오래 걸리는 초기화와 매 시작마다 루틴을 반복할 필요가 없어진다. LD_BIND_NOW, 즉, 프로그램의 시작에 모든 함수의 심볼을 찾아두었고, 출발하기 직전의 자식 프로세스를 계속 만들어서 수행하기 때문에 따로 초기화 과정이 필요하지도 않다. 더군다나, 주소가 쓰기를 수행할 때까지 부모 프로세스와 같은 주소공간을 공유하는 copy-on-write 성질 덕분에, fork()의 속도는 execve() 보다 훨씬 더 빠르다.
2.1.4 Persistent Mode
fork()를 지속해서 사용하는 것 역시 bottleneck이 될 수 있다. 이를 개선하기 위해 각각의 test case마다 fork를 수행하지 않고, 반복문을 사용해 한 회 수행시 그 내용을 패치하는 방식으로 대체할 수 있다.
2.2 Smart Scheduling
현대의 커버리지 기반 fuzzer는 저마다의 우선순위를 갖고 퍼징 파이프라인 내에 있는 입력들을 스케줄링한다. 스케줄러의 목적은 일반적으로 종합적인 커버리지를 높이고, 스마트한 테스트케이스 선택을 통해 버그 탐지를 수행하는 것이다.
2.2.1 AFLFast
AFLFast는 새로운 branch를 탐색하고 더 많은 버그를 찾기 위해서 낮은 주기로 탐색된 path에 주목하였다. 그들은 두 가지 문제를 강조했다.
- 낮은 주기의 path를 탐색하려면, fuzzer가 seed를 어떻게 선택해야 할까?
- 개별 seed에서 만들어진 입력의 양을 조율할 수 있을까?
첫 번째 문제를 해결하기 위해 새로운 탐색 전략들을 만들었고, 두 번째 문제를 해결하기 위해 퍼징 과정에서 수집된 인자로부터 seed의 값을 계산하는 6개의 강력한 스케줄러를 구현하였다.
2.2.2 MOpt
seed scheduling과 별개로 MOpt는 mutation scheduling을 도입하였다. custom Particle Swarm Optimizaion 알고리즘을 사용하였으며, Pilot과 Code 모듈을 도입하여 효율성을 기반으로 연산을 평가하고 이를 기반으로 mutation을 생성한다. 이러한 최적화를 통해, fuzzer가 코드 커버리지를 더 빨리 찾을 수 있도록 만들었다.
2.3 Bypassing Roadblocks
Roadblock은 본질적으로 블라인드 변이로는 뚫기 어려운 입력 비교 패턴을 의미한다. 전형적으로, magic number나 checksum 값이 이에 해당한다.

2.3.1 LAF-Intel
이 문제를 해결하기 위해 멀티 바이트 비교 연산을 여러 개의 싱글 바이트 비교 연산으로 바꾸어서 우회하는 LAF-Intel이 나왔다. 이는 ≥ 연산을 두 개의 연산(>, ==)으로 나누고, 모든 부호 없는 정수 비교는 8비트의 다중 비교 연산으로 이루어지도록 하고, 부호 있는 정수 비교를 부호 있는 연산과 부호 없는 연산으로 바꾼다. LLVM pass를 통한 구현을 목적에 둔 이 방법은, 정수 비교 연산과 strcmp와 같은 문자열 비교 연산을 컴파일 타임에 분리한다.
2.3.2 RedQueen
그 외의 해결책으로는 kAFL을 기반으로한 RedQueen 퍼저는 새로운 방법을 고안했는데, 이는 I2S(Input-To-State, 최소 1개의 인자와 직접적인 영향이 있는 비교 연산 중 한 종류)에 중점을 두는 것이다. 코드 커버리지를 유지하는 정도에서 입력을 랜덤 바이트로 바꿈으로써, 입력에 대한 엔트로피를 증가시키는 colorization stage를 수행한다. 이때, I2S에 주목함으로써, fuzzer는 경우의 수를 줄여나갈 수 있다. 이후에 I2S Token을 입력으로 사용하여 패치를 수행한다고 하는데, 이 부분은 잘 모르겠다.
2.4 Mutate Structured Inputs
퍼저의 일반적인 문제는 변형을 거치고 나면, 너무 잘못된 입력이 생성돼서 파싱하다가 죽어버린다는 것이다. 이에 대한 해결책은 입력 모델을 사용하여 생성된 입력 공간을 효과적으로 줄이는 것이다. 이를 통해 피드백 기반 퍼저는 프로그램의 심층 경로를 탐색할 수 있다.
2.4.1 AFLSmart
Pham et al.은 AFL에 PEACH Fuzzer(structured black-box fuzzing)를 입력 모델로 사용함으로써, PEACH에 작성된 프로토콜에 대한 명세를 재사용할 수 있게 하였다. AFLSmart는 테스트케이스 자체를 파싱하여, 커버리지를 향상시키는데 도움을 준다. AFLSmart는 raw bytes가 아니라, 가상의 구조체(AST)를 변형함으로써, 고차원 적인 구조체 변형을 가능케한다.
3. A New Baseline for Fuzzing
AFL++은 이름만 봐도 알겠지만, AFL의 파생된 버전이다. AFL의 기본 내용을 바탕으로, 이뤄진 수많은 연구들을 총집합해서 AFL++만의 향상된 기능들이 많이 있다. 논문에서 저자는 AFL++이 AFL을 대체하는 새로운 프레임워크가 되기를 바라고, 향후 연구들이 AFL++을 반석으로 이뤄지기를 희망한다. AFL++의 기능은 여기에서 논의된 것에서 제한되지 않으며, 적지만 효율적인 개선에 대해 제대로 이해하고자 한다면 AFL++ Document를 참고하라.
3.1 Seed Scheduling
AFL++은 AFLFast를 기반으로 강력한 스케줄링을 추가하였다. 이는 AFLFast의 모든 스케줄링(fast, coe, explore, quad, lin, exploit)을 포함한다. 이 스케줄링들은 다음 변수에 대한 함수들이다.
- 큐에서 시드를 고르는데 걸리는 시간
- 해당 시드에서 동일한 커버리지를 가지고 생성되는 입력의 수
- 동일한 커버리지를 가지고 생성되는 입력의 평균 개수
default scheduler는 explore이다. AFL++은 여기에 mmopt와 rare 스케줄링을 추가하였다. mmopt는 새롭게 발견된 path를 더 깊게 탐색하기 위해, 그러한 path를 탐색한 seed의 가중치를 높인다. rare는 다른 모든 스케줄러와 달리, seed가 돌아가는 시간을 무시하며 다른 seed에서 발견되지 않은 path에 가중치를 높인다.
3.2 Mutators
3.2.1 Custom Mutator API
AFL++은 학계에서 새로운 연구를 진행할 것을 고려해, 새로운 스케줄링, 뮤테이션, 그리고 최소화를 AFL++에서 빌드할 수 있도록 만들었다. 다음과 같은 함수들이 구현되어있다.
- afl_custom_(de)init
- afl_custom_queue_get
- afl_custom_fuzz
- afl_custom_havoc_mutation
- afl_custom_post_process
- afl_custom_queue_new_entry
- afl_custom_init_trim
- afl_custom_trim
- afl_custom_post_trim
3.2.2 Input-To-State Mutator
AFL++은 RedQueen의 I2S replacement를 기반으로 mutator를 구현하였는데, 몇 가지 최적화를 추가하였다. 입력의 엔트로피를 증가시키는 colorization stage가 실행 속도의 저하를 초래했기에, 단순히 이를 방지하는 조건을 추가하였다. 또한, 비교 연산에 있어서 흥미로운 입력을 만들지 못한다면, 다음 번 fuzzing 때는 그 연산에 대한 확률을 낮춘다. 이는 I2S처럼 보이지만, 그렇지 않은 비교 연산에 많은 시간을 쏟는 것을 방지한다.
3.2.3 MOpt Mutator
AFL++은 MOpt의 Core와 Pilot 모드를 구현하였고, I2S 모듈도 결합할 수 있다. 기본 mutation 모드에 MOpt를 함께 지원하는 것이다.
3.3 Instrumentations
AFL++에서는 LLVM, GCC, QEMU, Unicorn 등을 계측(Instrumentation)하기 위해 사용할 수 있다.

NeverZero는 Instrumentation에 사용되는 백엔드와 별개로, AFL의 hitcount 메커니즘(공유 메모리에 해시 값을 인덱스로 하여 값을 상승시켜 coverage를 측정하는 방법)을 최적화하여 만든 것이다. 기존의 edge execution에 대한 count로 비트맵을 사용하는 것은 256번 실행됐을 때, 다시 0으로 초기화되어 fuzzer를 불안정한 상태로 만든다는 단점이 있었다. 이를 해결하기 위한 두 가지 방법이 존재했는데, NeverZero와 Saturated Counters이다. 전자는 항상 carry flag를 세팅하는 것이고, 후자는 255에서 path count를 얼리는 것이다. NeverZero가 성능 면에서 효율적이었기 때문에 이를 default로 세팅하였다.
3.3.1 LLVM
LLVM 모드를 사용할 경우, AFL++은 단순한 edge coverage 말고도 다양한 커버리지 매트릭스를 제공한다.
- Context-sensitive Edge Coverage : 방문한 basic block의 ID 대하여 이전 block의 ID를 XOR함으로써, 특정 블록이 실행되었는가가 아니라, 특정 블록이 어떤 블록으로부터 실행되었는가를 저장하는 방식
- Ngram : edge를 기록할 때, 현재 블록과 이전 블록을 계산하는 것이 아니라, 현재 블록과 N-1 이전의 블록을 고려하는 방식(2≤N≤16)
그 외에도 floating-point 비교 연산을 분해하는 LAFIntel(비디오 디코더나 JS 인터프리터에 효과적), 문자열 비교 연산은 더 효과적으로 사용할 수 있게 되었고, 여기엔 정리하지 않았지만 CmpLog pass도 사용 가능하다. 또한, 계측을 할 때, 특정 소스 모듈을 지정할 수 있고, 공유 메모리를 통해 입력을 전달할 수 있다. 마지막으로, InsTrim patch를 사용한다면, 의미 없는 곳에 계측 코드를 추가하지 않아 성능 향상을 추구할 수도 있다고 한다.
3.3.2 GCC
조금 오래된 afl-gcc와 함께, AFL++은 gcc 플러그인도 지원한다. 지원되는 기능은 LLVM과 동일하지는 않지만, 최종적으로는 그렇게 되는 것이 목표이다.
3.3.3 QEMU
AFL++의 QEMU 모드는 바이너리를 패치하지 않고, 에뮬레이션 타임에 계측을 수행한다. 또한, QEMU에서 로깅을 할 때, 에뮬레이터 단에서 로깅하는 것이 아니라, 별도의 helper를 사용하여 로깅 루틴을 호출하는 방식을 이용하였고 이를 통해 2-3배의 평균 속도 향상을 이끌었다.
- CompareCoverage : LAFIntel와 유사한 방식으로 비교 연산을 분해한다. 코드 자체를 수정하는 LLVM pass와는 달리, 모든 비교 연산을 hooking하고 바이트 단위로 비교한다.
- Persistent Mode : WinAFL과 비슷하게 유저가 함수의 시작 주소를 지정하고, Fuzzer는 자동으로 Return address를 수정함으로써 반복할 수 있게끔 만든다. 꼭 함수의 시작이 아니더라도 return address에 대한 오프셋만 잘 전달하면 된다. 또는, 루프의 시작과 끝 주소를 지정함으로써, 두 주소 사이를 반복하게끔 할 수도 있다.
3.3.4 Unicornafl
Unicorn engine은 경량화된 멀티 아키텍쳐 CPU emulator 프레임워크이다. QEMU와 비슷한 거라고 생각하면 될 것 같다. 여튼, Unicorn engine에서 구현한 내부에서도 계측이 가능하도록 만든 것이 unicornafl이다. Unicorn engine은 읽고 쓸 메모리 혹은 레지스터, syscall에 대한 hook, 특정 조건에 따른 시작과 끝을 정의할 수 있는 API를 제공한다. AFL++은 이에 더해 C API, Rust와 Python binding을 구현하여 직접적으로 내외부가 데이터를 주고받을 수 있게끔 하였다.
3.3.5 QBDI
Android library 퍼징에 있어서, AFL++은 컴파일 타임에 LLVM을 사용하여 계측을 할 수도 있고, closed-source의 경우 QuarkslaB Dynamic binary Instrumentation(QBDI) 프레임워크를 활용하여 harness를 지원하기도 한다.
3.4 Platform Support
AFL++은 여러 개의 OS와 distribution에 대해 제공된다. 이는 GNU/Linux뿐만 아니라, Android, iOS, macOS, FreeBSD, OpenBSD, NetBSD에서 돌릴 수 있으며, 그리고 Debian, Ubuntu, NixOS, Arch Linux, FreeBSD, Kali Linux 등과 같은 distribution에서 패키지되어 있다. 게다가, AFL++의 QEMU 모드는 Wine 모드를 지니고 있으며, 이를 통해 GNU/Linux에서 Win32 binary를 퍼징할 수도 있다.
3.5 Snapshot LKM
AFL의 맥락 복구 기법은 fork를 기반하고 있으며, 이는 여러 타겟에 있어서 병목현상의 원인이 된다는 것은 익히 알려져있다. 따라서, AFL++은 Xu가 제작한 Perffuzz에 shout out하면서, 리눅스 커널 모듈을 포함하였다. Perffuzz는 process snapshot과 restore에 있어서 간단한 메커니즘을 구현하였다. 싱글 코어로 돌렸을 때 평균적으로 fork에 대비하여 2배까지의 성능 이득을 얻을 수 있었다. 그러나, fork의 lock으로 인해, 여러 개의 코어로 병렬 퍼징을 돌렸을 때 그 차이는 더욱 커졌다. fork가 아닌 snapshot을 사용하는 것은 프로그램을 recompile할 필요가 없다는 것을 의미하나, 일단 드라이버가 업로드된다면, 모듈의 존재가 자동으로 탐지된다.
5. Future Work
지난 수년 동안 AFL++ 프로젝트는 많은 진전을 일구어내고 있지만, 아직 해결해야 할 문제들이 남아있다.
5.1 Scaling
현재 AFL++을 멀티 스레드로 확장하는 것은 이상적이지 않은 상태이다. 입력(testcase)을 전송하는데 있어서, 파일 시스템을 사용하고 있고, 또한 LLVM이 백엔드로 구성되어 있지 않으며, 특정 대상에 있어서는 fork syscall에 의존하기 때문에, 커널 단에서 많은 오버헤드가 발생하고 있다. AFL++은 thread-safe하게 구현되었으며, 그 다음에는 multithreading을 지원하면서도 여러 개의 병렬 퍼저 사이의 동기화 오버헤드를 최소화하는 것이다.
5.2 Collision-Free instrumentation
AFL++에서는 basic block에 대한 계측을 위해 hash table을 제공하고 있다. 그러나, 이러한 테이블의 크기가 제한적이기 때문에 해시 충돌 가능성을 지니고 있다. 이는 속도와 정확성 사이의 trade-off이며, 근미래에는 소스 코드와 에뮬레이션을 통한 계측 모두에서 해결해야 할 문제이다.
5.3 Static Analysis for Optimal Fuzz Settings
이 연구에서 보여준 바와 같이, 우리는 AFL++의 조정 값에 대한 최적화 연구를 수행하였다. 현재 목표는 instrumentation, mutation, scheduling에 있어서 가장 최적화된 설정 값을 찾는 것이다. 그러나, 우리는 4장 챕터에서 보여준 바와 같이, 이는 타겟에 따라 상당히 달라진다.
그래서 향후에는 타겟에 대한 정적 분석을 통해, 최적화된 설정 값을 찾는 것을 목표로 할 것이다.
5.4 Plug-in System
현재 Custom Mutator가 연구자들에게 방대한 확장성을 제공하고 있으나, 최종 목표는 scheduler, executor and queue와 같은 토대부터 교체하고 기능을 추가할 수 있는 확장성을 제공하는 것이다.
6. Conclusion
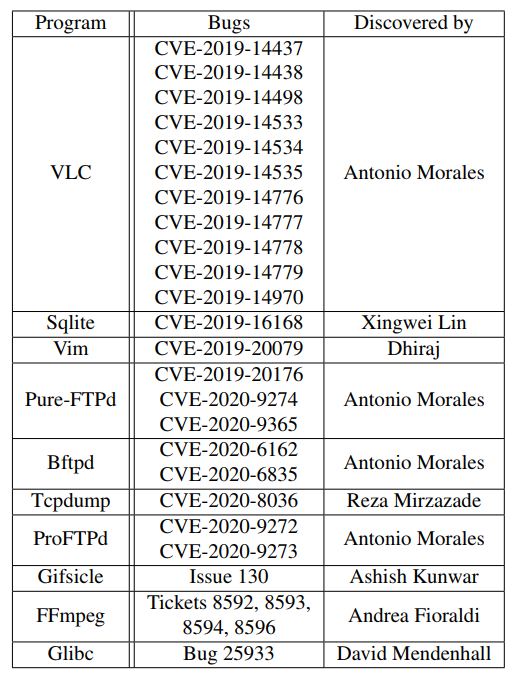
AFL++ 를 통해 여러 AFL 관련 연구를 집대성하고 각 도구의 장점이 되는 기능을 뽑아서 합쳤다. 실제로 AFL++를 이용해 찾은 취약점 목록은 아래와 같다.
AFL++는 현재 진행형이며, 앞으로도 많은 연구자들의 커뮤니티 참여를 바란다.